
Object 6D pose estimation methods can achieve high accuracy when trained and tested on the same objects. However, estimating the pose of objects that are absent at training time is still a challenge.
In this work, we advance the state-of-the-art in zero-shot object 6D pose estimation by proposing the first method that fuses the contribution of pre-trained geometric and vision foundation models
Unlike state-of-the-art approaches that train their pipeline on data specifically crafted for the 6D pose estimation task, our method does not require task-specific finetuning. Instead, our method, which we name PoMZ, combines geometric descriptors learned from point cloud data with visual features learned from large-scale web images to produce distinctive 3D point-level descriptors. By applying an off-the-shelf registration algorithm, like RANSAC, PoMZ outperforms all state-of-the-art zero-shot object 6D pose estimation approaches.
We extensively evaluate PoMZ across the seven core datasets of the BOP Benchmark, encompassing over a hundred objects and 20 thousand images captured in diverse scenarios. Our results are publicly available on the BOP Benchmark website, under the category Task 4: 6D localization of unseen objects — Core datasets. We will release the source code publicly.
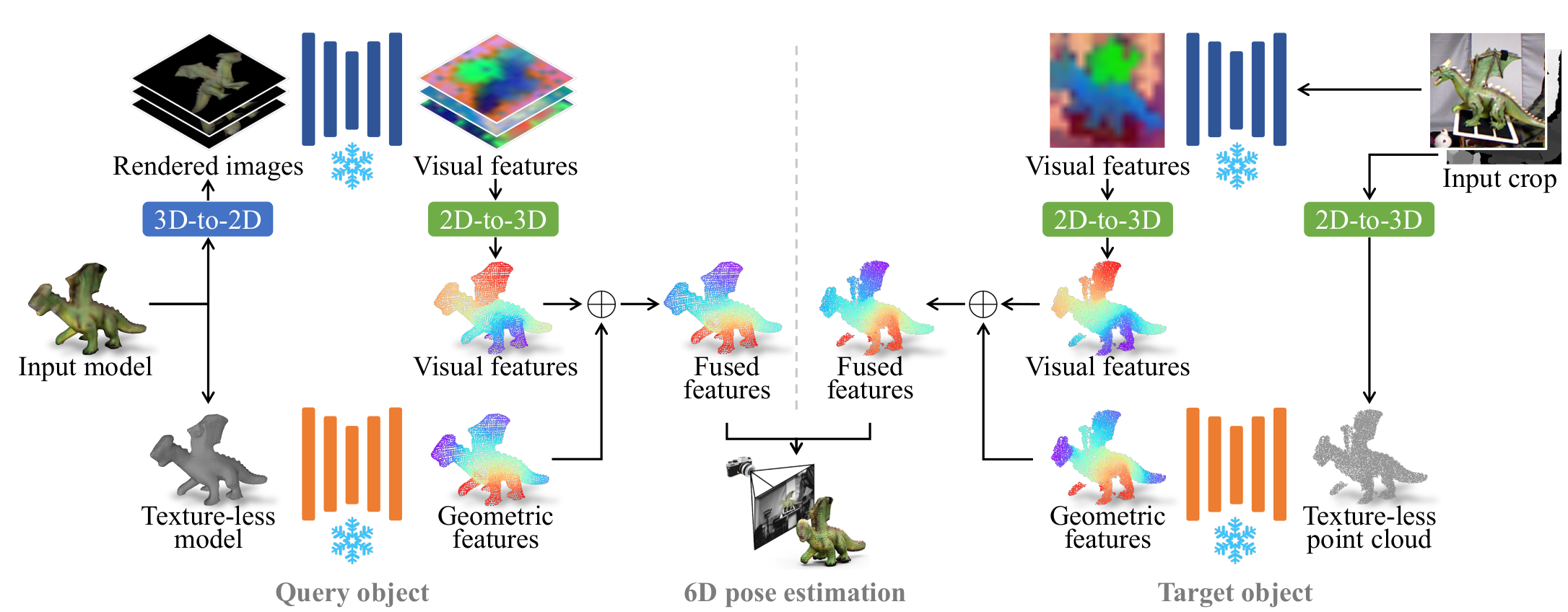
Given a 3D model of a novel query object and an RGBD image, we compute their geometric and visual features using frozen geometric and vision foundation models which do not require any task-speficic training.
We create rendered images from the 3D model to extract visual features of the query object, which we then back project to the object point cloud. Concurrently, we extract geometric features, which we then fuse with the visual features.
Similarly, we compute visual and geometric features of the target object imaged in the input crop, and fuse the two as before. Although the query and target objects are from two different modalities (a 3D model the former, and an RGBD image the latter), we employ the same vision and geometric encoders to compute their features.
Lastly, we input the fused features to a registration algorithm based on feature matching to estimate the object 6D pose.
@article{caraffa2023pomz,
title = {Object 6D pose estimation meets zero-shot learning},
author = {Caraffa, Andrea and Boscaini, Davide and Hamza, Amir and Poiesi, Fabio},
journal = {arXiv:2312.00947},
year = {2023}
}